KVMesh is a research and demonstration dabase. It exemplifies a wide variety of mesh-based scientific data expressed in key-value form suitable for processing by Big Data technologies such as Apache Spark or Hadoop.
 |
 |
|
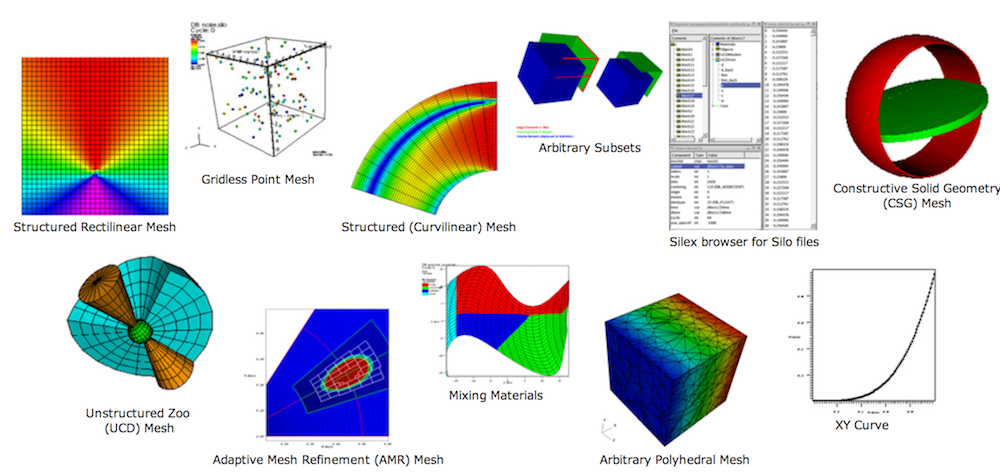
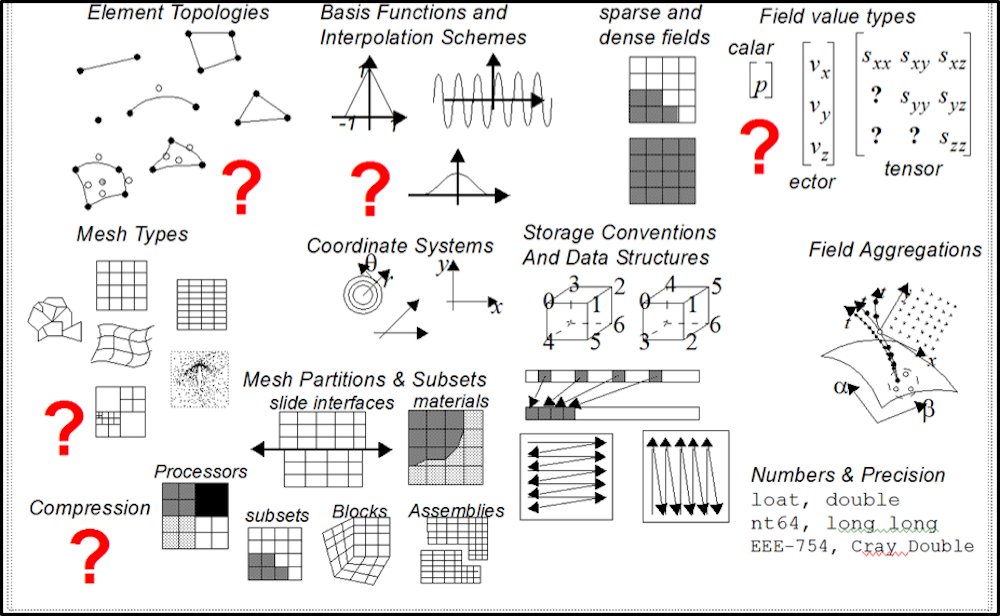
The pictures here (click to enlarge them) illustrate that mesh-based scientific data has a well defined data model, is highly structured and often rich and diverse in logical, geometrical and mathematical relationships. This is in stark contrast to unstructured text and key-value pairs typical of Big Data workflows.
These two kinds of data, mesh-based scientific data versus unstructured text and key-value pairs, could not represent two more incompatible data forms. Thus, a fundamental question is how to express mesh-based scientific data as unstructured text and key-value pairs so that it can be naturally and easily processed within off-the-shelf Big Data workflows.
The critical insight is to treat the nodes and zones of a scientific mesh as a collection of entities with attributes. Key-value pairs are then easily constructed using the mesh entities (nodes, elements, blocks, etc.) as the keys and their attributes (materials, variables, etc.) as the values.
Towards this end, the KVMesh database is a massive folder hierarchy of CSV text files consisting of key-value pairs from a vareity of data sources representative of various aspects of mesh-based scientific data.
The aim of the KVMesh database is to facilitate and inspire research and development of Big Data approaches to mesh-based scientific data query, analysis and visualization as well as to provide a focal point for the exchange of ideas aimed at the fusion of traditional HPC and Big Data solutions for scientific data.