 |
The KVMesh database is designed to meaningfully represent data as though it spans the entire DOE Complex in a coherent and uniform way. The idea of a single, coherent database that spans the entire DOE complex in a uniform way is a revolutionary concept in its own right. However, the true power of Big Data technology and what it makes possible cannot be fully demonstrated without starting from a sufficiently wide scope.
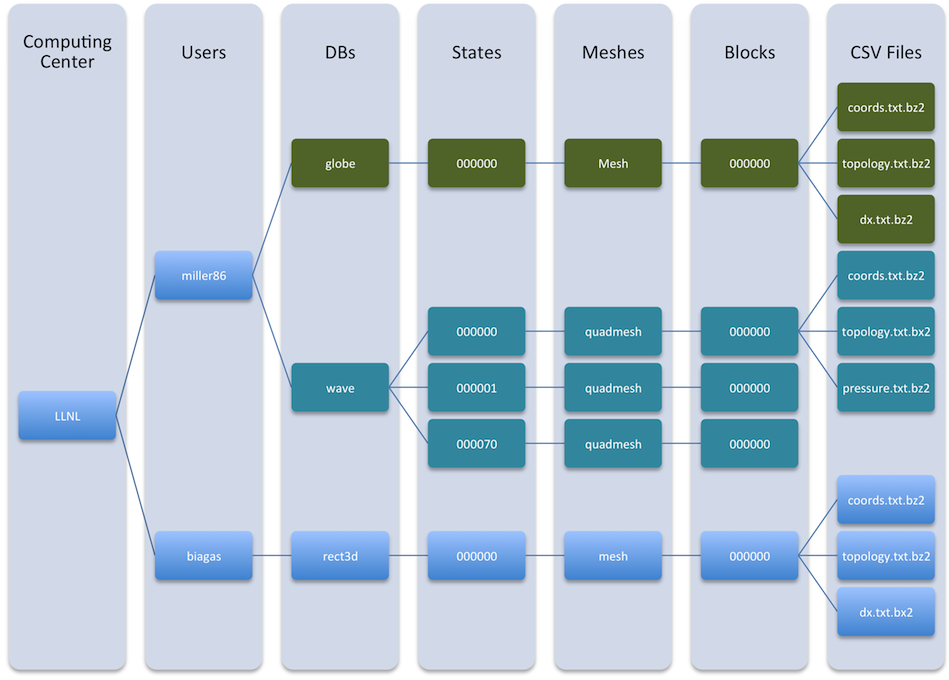
In a nutshell, the KVMesh database is a massive folder hierarchy of Bzip compressed CSV text files. The hierarchy is based on these observations…
- DOE sites have Computing Centers
- Computing Centers have Users
- Users have Datasets
- Datasets have States
- States have Meshes
- Meshes have Blocks
- Blocks have Data
- Mesh topology (connectivity)
- Materials
- Fields
The leaves in this taxonomy is where raw data actually lives. It includes such things as the list of mesh entities (e.g. nodes and zones) comprising a block, the coordinates of a block, fields (e.g. pressure, velocity, mass) defined on a block, the material decomposition of a block, etc. In particular, each topological entity is uniquely identified across the entire KVMesh database.
By setting upper bounds on the total number of objects to be permitted in each of these categories, we can establish an upper bound on the total number of bits required in a mesh entity key to uniquely identify it across the entire KVMesh database. By proper design of mesh entity keys, given any mesh entity, we can identify which DOE site it came from, which computing center at that site, which user at that center, which dataset of that user, which state of that dataset, which mesh of that state and which block of that mesh.
With this over-arching design, we enable a Big Data workflow with the ability to perform queries of arbitrary scope. The underlying Big Data machinery required to perform any query of any scope is basically the same and is independent of scope. The only difference is the compute resources required to respond in a given target time constraint. For example, a query for maximum temperature of one user’s dataset for one state vs. the maximum temperature over all states vs. the maximum temperature over several different datasets is the same query except executed from different points in the folder hierarchy.
We plan to present more details here on this page at a future data. Until then, please refer to this page.